如果两个无向图 $G$ 和 $H$ 满足以下条件,则称它们是同构的: 它们拥有相同数量的顶点; 在它们的顶点之间存在一一对应关系,使得对于 $G$ 中的任意两个不同顶点,当且仅当它们在 $H$ 中的对应顶点之间存在边时,它们之间才存在边。
例如,尽管外观不同,但以下两个图是同构的:
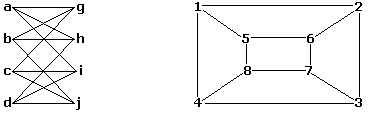
展示这两个图同构的一种可能的一一对应关系为 $\{a-1, b-6, c-8, d-3, g-5, h-2, i-4, j-7\}$,当然也存在其他对应关系。
图 $G$ 的子图是指一个图,其顶点集和边集分别是 $G$ 的顶点集和边集的子集。注意 $G$ 本身也是它自己的一个子图。以下示例展示了一个图及其一个子图:
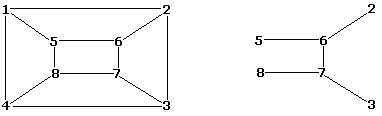
如果图 $G$ 至少包含一个同构于 $H$ 的子图 $H'$,则称图 $G$ 包含另一个图 $H$。下图展示了一个包含图 $H$ 的图 $G$。
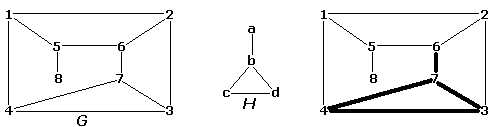
任务
给定两个无向图 $G$ 和 $H$,请构造 $G$ 的一个子图 $G'$,使得: $G$ 和 $G'$ 的顶点数量相同; $G'$ 不包含 $H$。
显然,满足上述属性的子图 $G'$ 可能有很多。请构造其中一个边数尽可能多的子图。
BASE ALGORITHM
解决此问题最基本的策略可能是按照输入文件中给出的顺序考虑 $G$ 的边,然后尝试将它们逐一添加到 $G'$ 中,并在每一步验证 $G'$ 是否包含 $H$。该贪心算法的正确实现可以获得一些分数,但存在更好的策略。
CONSTRAINTS
$3 \le m \le 4$,$H$ 的顶点数。 $3 \le n \le 1000$,$G$ 的顶点数。
INPUT
你将获得 10 个文件 forbidden1.in 到 forbidden10.in,每个文件包含以下数据:
- 第 1 行:包含两个空格分隔的整数,分别为 $m$ 和 $n$。
- 接下来的 $m$ 行:每行包含 $m$ 个空格分隔的整数,按顺序 $1, \dots, m$ 表示 $H$ 的一个顶点。如果 $H$ 中顶点 $i$ 和 $j$ 之间有边,则该部分第 $j$ 行的第 $i$ 个元素为 1,否则为 0。
- 接下来的 $n$ 行:每行包含 $n$ 个空格分隔的整数,按顺序 $1, \dots, n$ 表示 $G$ 的一个顶点。如果 $G$ 中顶点 $i$ 和 $j$ 之间有边,则该部分第 $j$ 行的第 $i$ 个元素为 1,否则为 0。
注意,除第 1 行外,上述输入表示 $H$ 和 $G$ 的邻接矩阵。
OUTPUT
你必须提供 10 个文件,每个输入对应一个输出文件。每个文件必须包含以下数据:
- 第 1 行:文件头。文件头必须包含
#FILE forbidden K,其中 $K$ 是 1 到 10 之间与所解决的输入文件对应的数字。 - 第 2 行:包含一个整数 $n$。
- 接下来的 $n$ 行:每行包含 $n$ 个空格分隔的整数,按顺序 $1, \dots, n$ 表示 $G'$ 的一个顶点。如果 $G'$ 中顶点 $i$ 和 $j$ 之间有边,则该部分第 $j$ 行的第 $i$ 个元素为 1,否则为 0。
注意,除第 1 行和第 2 行外,上述输出表示 $G'$ 的邻接矩阵。注意,可能存在许多合法的输出,上述输出格式是正确的,但不一定是最优的。
GRADING
你的得分将取决于你输出的 $G'$ 中的边数。只有当输出文件满足任务规范时,你才能获得非零分数。如果满足,你的得分计算如下:设 $E_y$ 为你输出中的边数,$E_b$ 为基础算法计算出的 $G'$ 中的边数,$E_m$ 为所有参赛者提交的输出中边数的最大值。该测试点的得分将为:
- 若 $E_y \le E_b$,得分为 $30 \cdot E_y / E_b$;
- 若 $E_y > E_b$,得分为 $30 + 70(E_y - E_b) / (E_m - E_b)$。