ICP (International Cosmetic Perfection) 公司计划对 $m$ 种新化妆品进行偏好调查,以了解哪种化妆品最受欢迎。为了进行这项调查,ICPC 选择了 $n$ 名评估员。每位评估员必须提交一份关于这 $m$ 种化妆品的偏好排序列表。每位评估员对化妆品的评分规则如下:
- 评估员可以用正整数对化妆品进行排名,但这些正整数不一定是连续的。数值越小的正整数代表越受欢迎,数值第二小的正整数代表受欢迎程度次之,依此类推。
- 评估员可以给多种化妆品相同的偏好值。这表示该评估员对这些化妆品没有偏好差异。
- 评估员可以不对某些化妆品进行排名。未排名的化妆品在列表中标记为数字 $0$。这表示该评估员严格偏好所有已排名的化妆品,胜过所有未排名的化妆品,且对所有未排名的化妆品之间没有偏好差异。
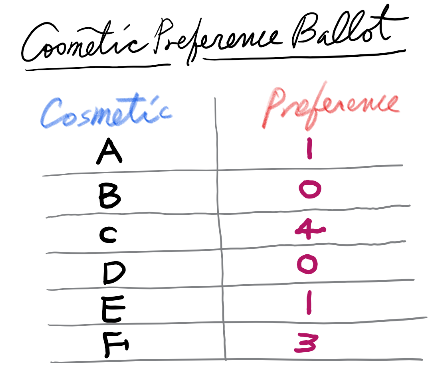
右图显示了一位评估员提交的关于六种化妆品 $A, B, C, D, E, F$ 的偏好排序列表。化妆品 $A, C, E, F$ 分别被赋予了不连续的整数 $1, 4, 1, 3$。另外两种化妆品 $B$ 和 $D$ 未被排名,因此标记为 $0$。$A$ 和 $E$ 具有相同的偏好值,且由于它们的偏好数值是最小的正整数,因此它们是最受欢迎的化妆品。未排名的 $B$ 和 $D$ 比已排名的化妆品受欢迎程度低。结果,该评估员的偏好顺序为 $A = E > F > C > B = D$,其中 $X > Y$ 表示 $X$ 严格优于 $Y$,$X = Y$ 表示偏好程度相同。
在这次偏好调查中,从 $n$ 名评估员的反馈中,哪些化妆品是最受欢迎的?我们现在必须定义一种化妆品优于另一种化妆品的规则。令 $d(X, Y)$ 为严格偏好 $X$ 胜过 $Y$ 的评估员人数。从 $X$ 到 $Y$ 的路径是一系列不同的化妆品 $C_1, \dots, C_k$,使得 $C_1 = X, C_k = Y$,且对于每个 $t = 1, \dots, k-1$,都有 $d(C_t, C_{t+1}) > d(C_{t+1}, C_t)$。该路径的偏好指数定义为对于 $1 \le t < k$,$d(C_t, C_{t+1})$ 的最小值。对于由从 $X$ 到 $Y$ 的路径连接的两个不同化妆品 $X$ 和 $Y$,偏好强度 $S(X, Y)$ 定义为从 $X$ 到 $Y$ 的所有路径中偏好指数的最大值。如果不存在从 $X$ 到 $Y$ 的路径,则 $S(X, Y)$ 定义为零。当且仅当对于除 $X$ 之外的每个 $Y$,都有 $S(X, Y) \ge S(Y, X)$ 时,化妆品 $X$ 才是本次调查中最受欢迎的化妆品之一。请注意,已知对于此类调查,至少存在一种最受欢迎的化妆品。
给定 $n$ 名评估员对 $m$ 种化妆品的偏好列表,编写一个程序输出所有最受欢迎的化妆品。
输入格式
程序从标准输入读取数据。输入的第一行包含两个整数 $m$ 和 $n$ ($1 \le m \le 500, 1 \le n \le 500$),其中 $m$ 是化妆品的数量,$n$ 是评估员的数量。化妆品编号为 $1$ 到 $m$,评估员编号为 $1$ 到 $n$。在接下来的 $n$ 行中,第 $i$ 行包含 $m$ 个非负整数,表示评估员 $i$ 对 $m$ 种化妆品的偏好值。偏好值按化妆品 $1$ 到 $m$ 的顺序排列。列表中的零值表示评估员未对相应的化妆品进行排名。偏好值不超过 $10^6$。
输出格式
程序应写入标准输出。输出仅一行。该行应包含最受欢迎的化妆品编号。这些化妆品编号必须按升序排列。
样例
样例输入 1
3 4 1 1 1 0 0 0 2 2 2 3 3 3
样例输出 1
1 2 3
样例输入 2
4 5 1 0 1 1 1 1 5 2 2 1 3 6 0 1 0 1 1 2 2 2
样例输出 2
1 2
样例输入 3
5 4 0 1 0 2 1 1 7 2 1 0 4 5 2 3 3 1 2 9 0 2
样例输出 3
5