Đây là một bài toán tương tác với hai lượt chạy (chạy hai lần).
Trong bài toán này, chúng ta xét các cây có gốc không có thứ tự. Một cây có gốc không có thứ tự bao gồm một gốc, có thể có không hoặc nhiều con. Mỗi con, đến lượt nó, lại là một cây có gốc không có thứ tự. Như tên gọi, thứ tự liệt kê các con không quan trọng. Nghĩa là, các cây được minh họa trong hình dưới đây là cùng một cây có gốc không có thứ tự. Sau đây, chúng ta sẽ gọi tắt cây có gốc không có thứ tự là cây.
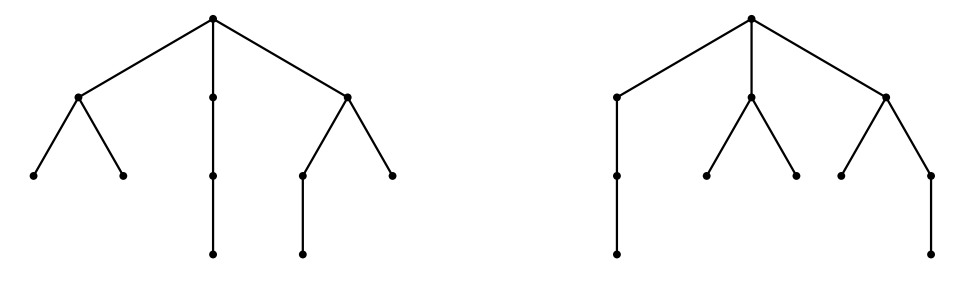
Bất kỳ cây nào cũng có thể được mã hóa thành một dãy ngoặc đều (sau đây gọi là RBS) như sau:
- Một cây chỉ gồm một đỉnh duy nhất được mã hóa thành "
()". - Giả sử sau khi loại bỏ gốc, cây tách thành các cây con $t_1, t_2, \ldots, t_k$, trong đó $k$ là số con của gốc của cây ban đầu. Gọi $s_1, \ldots, s_k$ là các xâu mã hóa các cây $t_1, \ldots, t_k$. Khi đó, với mọi hoán vị $a=[a_1, a_2, ..., a_k]$ của các số từ $1$ đến $k$, cây ban đầu có thể được mã hóa bằng RBS "
($s_{a_1}s_{a_2}\ldots s_{a_k}$)".
Lưu ý rằng cùng một cây có thể được mã hóa bằng các RBS khác nhau. Ví dụ, cây được minh họa trong hình dưới đây có thể được mã hóa bằng RBS "(()(()))" hoặc "((())())".
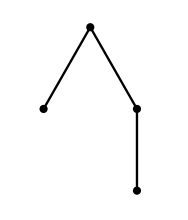
Bạn cần học cách mã hóa một dãy cây tùy ý $u_1, \ldots, u_n$ thành một cây có gốc duy nhất $w$. Để kiểm tra tính đúng đắn của phương pháp mã hóa của bạn, lời giải của bạn sẽ được chạy hai lần.
Lượt chạy đầu tiên
Trong lượt chạy đầu tiên, chương trình của bạn nhận đầu vào là $n$ RBS, mỗi RBS biểu diễn mã $s_i$ của một cây có gốc nào đó. Đáp lại, chương trình của bạn phải xuất ra một RBS mã hóa một cây có gốc $w$ nào đó. Trong các nhiệm vụ con khác nhau, có các ràng buộc khác nhau về số đỉnh của cây $w$ phụ thuộc vào tổng số đỉnh của các cây ban đầu.
Lượt chạy thứ hai
Trong lượt chạy thứ hai, chương trình của bạn nhận đầu vào là một RBS duy nhất mã hóa cây $w$ mà chương trình của bạn đã xuất ra trong lượt chạy đầu tiên. Lưu ý rằng bất kỳ RBS hợp lệ nào mã hóa cây $w$ đều có thể được cung cấp làm đầu vào, không nhất thiết phải là RBS đã được chương trình của bạn xuất ra trong lượt chạy đầu tiên.
Đáp lại, chương trình của bạn phải xuất ra các RBS mã hóa cùng các cây đã được cung cấp trong lượt chạy đầu tiên, theo đúng thứ tự. Đối với mỗi cây, bạn có thể xuất ra bất kỳ RBS nào mã hóa nó, nhưng thứ tự của các cây trong dãy phải giống như trong lượt chạy đầu tiên của chương trình.
Giao tiếp
Tại đầu mỗi lượt chạy, chương trình của bạn phải đọc một số nguyên $t$, bằng 1 hoặc 2 — số hiệu lượt chạy.
Lượt chạy đầu tiên
Trong lượt chạy đầu tiên, bạn cần xử lý nhiều test case. Mỗi test case được cung cấp trên đầu vào chuẩn một cách tương tác, nghĩa là trước khi đọc test case tiếp theo, chương trình của bạn phải xuất ra câu trả lời cho tất cả các test case trước đó và xóa bộ đệm đầu ra chuẩn.
Dòng đầu tiên của mỗi test case chứa một số nguyên $n$ — số lượng cây cần mã hóa. Nếu $n$ bằng $0$, nghĩa là tất cả các test case đã được xử lý và chương trình nên kết thúc. Ngược lại, $n$ dòng tiếp theo chứa mô tả của các cây.
Mỗi cây được xác định bởi một xâu $s_i$ duy nhất gồm các ký tự "(" và ")" — RBS mã hóa cây thứ $i$ theo cách được mô tả trong đề bài. Dữ liệu đảm bảo rằng $s_i$ biểu diễn một cây hợp lệ.
Với mỗi test case, chương trình phải xuất ra một RBS mã hóa một cây $w$ nào đó. Sau khi xuất ra cây, bạn phải xuất ra một ký tự xuống dòng và xóa bộ đệm đầu ra.
Trong bài toán này, hành vi của chương trình giám khảo trong lượt chạy đầu tiên là thích ứng. Điều này có nghĩa là chương trình giám khảo trong lượt chạy đầu tiên có thể sử dụng các cây $w$ do bạn xuất ra trong các test case trước của test hiện tại khi tạo ra test case mới.
Lượt chạy thứ hai
Trong lượt chạy thứ hai, bạn cần xử lý nhiều test case.
Mỗi test case được xác định bởi một xâu $s$. Nếu xâu $s$ bằng "0", thì bạn đã xử lý tất cả các test case và chương trình nên kết thúc.
Ngược lại, $s$ chứa một RBS nào đó mã hóa một cây $w$ mà chương trình đã xây dựng trong lượt chạy đầu tiên.
Với mỗi cây như vậy, bạn phải xuất ra một số nguyên $n$ trên một dòng riêng — số lượng cây đã được giải mã.
Trong dòng tiếp theo, bạn phải xuất ra $n$ RBS mã hóa, theo đúng thứ tự, cùng các cây đã được mã hóa bởi các xâu $s_1, \ldots, s_n$ được cung cấp trong lượt chạy đầu tiên, trên một dòng duy nhất, phân tách chúng bằng ký tự "+". Ví dụ, nếu bạn cần xuất ra các RBS "(())" và "(()())" theo thứ tự đó, đầu ra phải là: "2" ở dòng đầu tiên, và "(()())+(()())" ở dòng thứ hai.
Sau khi xuất ra số $n$ và xuất ra xâu mô tả các cây, bạn phải in một dòng mới và xóa bộ đệm đầu ra.
Trong mỗi test case ở lượt chạy thứ hai, chương trình của bạn có thể được cung cấp bất kỳ cây nào thu được trong lượt chạy đầu tiên.
Ghi chú
Đừng quên in một dòng mới sau mỗi lần xuất. Tham khảo hướng dẫn dành cho thí sinh để biết cách xóa bộ đệm đầu ra đúng cách trong các bài toán tương tác.
Nhiệm vụ con
Gọi $s$ là tổng độ dài của các RBS trong một test case, và $m$ là kích thước đầu ra của chương trình của bạn trong lượt chạy đầu tiên cho test case này. Với mỗi nhiệm vụ con, một hàm $f(x)$ được định nghĩa. Một nhiệm vụ con được coi là đạt nếu với mỗi test case $m \leq f(s)$ thỏa mãn, và nếu tất cả các cây được tái tạo chính xác.
Gọi $t_i$ là số đỉnh của cây thứ $i$. Khi đó độ dài của xâu $s_i$ là $2t_i$.
Gọi $S$ là tổng của $s$ trên tất cả các test case của một bài kiểm tra. Dữ liệu đảm bảo rằng trong mỗi bài kiểm tra $S$ không vượt quá $10^6$, và số lượng test case không vượt quá $100$.
| Nhiệm vụ con | Điểm | $f(x)$ | $S$ | Bổ sung | Các nhiệm vụ con bắt buộc |
|---|---|---|---|---|---|
| 1 | 13 | $f(x) = x + 2000$ | $S \le 200\,000$ | Trong lượt chạy thứ hai, các RBS được cung cấp giống hệt với các RBS do lời giải của bạn xuất ra trong lượt chạy đầu tiên. | |
| 2 | 7 | $f(x) = x + 2000$ | $S \le 200\,000$ | $t_1 < t_2 < \ldots < t_n$ | |
| 3 | 6 | $f(x) = x + 2000$ | $S \le 200\,000$ | $n = 2$ | |
| 4 | up to 34 | $f(x) = 4 \cdot x + 2000$ | $S \le 200\,000$ | ||
| 5 | up to 11 | $f(x) = x + 2000$ | $t_1 = t_2 = \ldots = t_n > 1$ | ||
| 6 | up to 9 | $f(x) = x + 2000$ | $t_i > 1$ | 5 | |
| 7 | up to 20 | $f(x) = x + 2000$ | 1 -- 6 |
Nhiệm vụ con thứ tư được tính điểm theo công thức sau. Gọi $k = \max\left(0, \dfrac{m - 2000}{s}\right)$ cho mỗi test case. Hàm $\operatorname{score}(k)$ được định nghĩa như sau:
| $k$ | $\operatorname{score}(k)$ |
|---|---|
| $\leq 1{,}5$ | $34$ |
| $2$ | $20$ |
| $3$ | $10$ |
| $4$ | $5$ |
| $> 4$ | $0$ |
Đối với các giá trị trung gian của $k$, hàm được tính tuyến tính giữa các hàng liền kề của bảng và làm tròn đến số nguyên gần nhất.
Điểm cho một bài kiểm tra là giá trị nhỏ nhất của $\operatorname{score}(k)$ trên tất cả các test case trong bài kiểm tra. Điểm cho một nhiệm vụ con là giá trị nhỏ nhất của điểm của các bài kiểm tra trong nhiệm vụ con đó.
Các nhiệm vụ con 5, 6 và 7 cũng được tính điểm bằng công thức. Gọi $c = \max(0, m - s)$ cho mỗi test case. Hàm $\operatorname{score}(c)$ được định nghĩa như sau:
| $c$ | $\operatorname{score}(c)$, nhiệm vụ con 5 | $\operatorname{score}(c)$, nhiệm vụ con 6 | $\operatorname{score}(c)$, nhiệm vụ con 7 |
|---|---|---|---|
| $\leq 30$ | $11$ | $9$ | $20$ |
| $100$ | $7$ | $7$ | $14$ |
| $200$ | $4$ | $4$ | $8$ |
| $2000$ | $2$ | $2$ | $4$ |
| $> 2000$ | $0$ | $0$ | $0$ |
Đối với các giá trị trung gian của $c$, hàm được tính tuyến tính giữa các hàng liền kề của bảng và làm tròn đến số nguyên gần nhất.
Điểm cho một bài kiểm tra là giá trị nhỏ nhất của $\operatorname{score}(c)$ trên tất cả các test case trong bài kiểm tra. Điểm cho một nhiệm vụ con là giá trị nhỏ nhất của điểm của các bài kiểm tra trong nhiệm vụ con đó.
Ví dụ
Dữ liệu vào 1
1 3 () (()) (()()) 1 ((())()) 0
Dữ liệu ra 1
((()(()()))) ((((((((()))))))))
Dữ liệu vào 2
2 ((((((((())))))))) (((()())())) 0
Dữ liệu ra 2
1 (()(())) 3 ()+(())+(()())