Many diseases are often caused by genetic mutations. Such genetic mutations arise from a normal DNA sequence through inheritance over several generations. In other words, a normal DNA sequence can produce different genetic sequences through various mutations. A fundamental problem in bioinformatics research is, for a given DNA sequence, to determine whether it is the same when reversed.
Let $X = x_1 x_2 \dots x_n$ be a given DNA sequence, where $x_i \in \{A, C, G, T\}$ and $1 \le i \le n$. For $1 \le i \le j \le n$, the substring of $X$ from $i$ to $j$, denoted as $x_i x_{i+1} \dots x_j$, is called the $[i, j]$ segment of $X$.
We define a segment of $X$ as "good" if and only if it reads the same from left to right as it does from right to left, i.e., the segment is a palindromic genetic sequence. Now, the Swiss biologist Wilson Edwards has posed $Q$ questions to you. Each question provides two integers $L$ and $R$, and you need to calculate how many distinct "good" sub-segments exist within the $[L, R]$ segment of $X$. If a sub-segment appears multiple times within $[L, R]$, it should only be counted once.
Input
The first line contains the sequence $X$. The next line contains an integer $Q$. The following $Q$ lines each contain two integers $L$ and $R$.
Output
For each query, output a single integer on a new line representing the answer.
Constraints
- For 10% of the data, $|S| \le 14800$, $Q \le 6500$
- For 40% of the data, $|S| \le 23\,000$, $Q \le 23\,000$
- For another 10% of the data, $|S| \le 5\,000$
- For another 20% of the data, $|S| \le 50\,000$, $Q \le 50\,000$
- For 100% of the data, $|S| \le 230\,000$, $Q \le 230\,000$
Examples
Input 1
ACCACTTGTCAGCT 5 1 5 3 8 2 7 4 13 5 6
Output 1
5 6 6 6 2
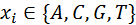
Mathematical definition of the DNA sequence elements