IP 查找是路由器进行数据包转发和分类的关键功能之一。通常,IP 查找可以简化为最长前缀匹配(Longest Prefix Matching, LPM)问题。即在转发信息库(FIB)中找到与输入数据包目的地址匹配的最长前缀,然后输出相应的下一跳信息。
基于 Trie 的解决方案是解决 LPM 最广泛使用的方法。如图 1(b) 所示,单比特 Trie(Uni-bit Trie)本质上是一棵二叉树。在单比特 Trie 上进行 LPM 处理,只需根据输入数据包的目的地址从根节点遍历到某个叶子节点即可。遍历路径上最长的前缀即为匹配项。为了减少单次查找的内存访问次数,我们可以将单比特 Trie 的若干连续层压缩为一层,从而将其转换为多比特 Trie(Multi-bit Trie)。
例如,假设步长数组(strides array)为 $\{3, 2, 1, 1\}$,那么我们可以将图 1(b) 中的单比特 Trie 转换为图 1(c) 所示的多比特 Trie。在转换过程中,某些前缀必须进行扩展。例如 $11(P_2)$,由于第一个步长为 3,它应该被扩展为 $110(P_2)$ 和 $111(P_2)$。但由于 $110(P_5)$ 在 FIB 中已经存在,因此我们只存储较长的前缀 $110(P_5)$。
多比特 Trie 显然可以减少树的深度,但问题在于如何构建一个内存消耗(内存单元数量)最小的多比特 Trie。如图 1 所示,单比特 Trie 有 23 个节点,总共消耗 46 个内存单元,而多比特 Trie 有 12 个节点,总共消耗 38 个内存单元。
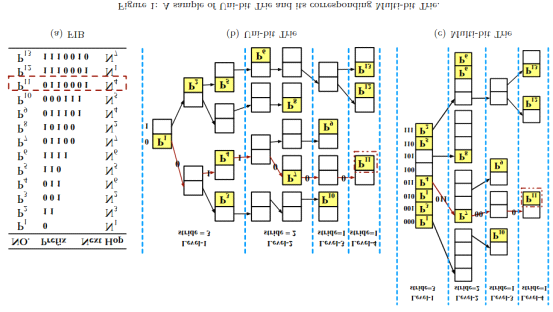
图 1:单比特 Trie 及其对应的多比特 Trie 示例。
输入格式
第一行是一个整数 $T$,表示测试用例的数量。 每个测试用例的第一行包含一个整数 $L$,表示单比特 Trie 的层数。 接下来的 $L$ 行表示单比特 Trie 每一层的节点数。 由于 IPv6 地址仅使用 64 位进行转发,单比特 Trie 最多有 64 层。此外,我们假设多比特 Trie 每一层的步长必须小于或等于 20。
输出格式
输出对应的多比特 Trie 所消耗的最小内存单元数。
样例
样例输入 1
1 7 1 2 4 4 5 4 3
样例输出 1
38