이 문제는 두 번의 실행(이중 실행)이 있는 인터랙티브 문제입니다.
이 문제에서는 순서가 없는 루트 트리(unordered rooted tree)를 다룹니다. 순서가 없는 루트 트리는 루트와, 루트가 가질 수 있는 0개 이상의 자식 노드들로 구성됩니다. 각 자식 노드는 그 자체로 순서가 없는 루트 트리입니다. 이름에서 알 수 있듯이, 자식 노드들이 나열되는 순서는 중요하지 않습니다. 즉, 아래 그림에 표시된 트리들은 동일한 순서가 없는 루트 트리입니다. 이하에서는 순서가 없는 루트 트리를 간단히 트리라고 부르겠습니다.
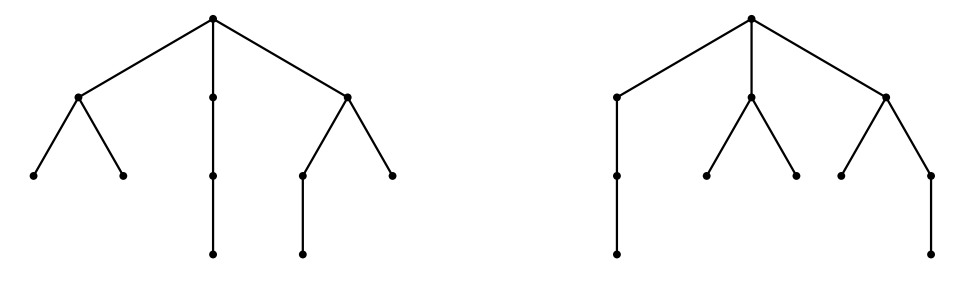
모든 트리는 다음과 같은 방식으로 정규 괄호 문자열(regular bracket sequence, 이하 RBS)로 인코딩될 수 있습니다:
- 단일 정점으로 구성된 트리는 "
()"로 인코딩됩니다. - 루트를 제거한 후 트리가 서브트리 $t_1, t_2, \ldots, t_k$로 나누어진다고 가정합니다(여기서 $k$는 원래 트리 루트의 자식 개수입니다). $s_1, \ldots, s_k$를 트리 $t_1, \ldots, t_k$를 인코딩하는 문자열이라고 합시다. 그러면 $1$부터 $k$까지의 숫자의 임의의 순열 $a=[a_1, a_2, ..., a_k]$에 대해, 원래 트리는 RBS "
($s_{a_1}s_{a_2}\ldots s_{a_k}$)"로 인코딩될 수 있습니다.
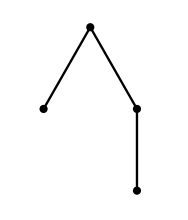
같은 트리가 서로 다른 RBS로 인코딩될 수 있다는 점에 유의하십시오. 예를 들어, 아래 그림에 표시된 트리는 RBS "(()(()))" 또는 "((())())"로 인코딩될 수 있습니다.
여러분은 임의의 트리 순서 $u_1, \ldots, u_n$을 단일 루트 트리 $w$로 인코딩하는 방법을 배워야 합니다. 인코딩 방법이 올바른지 확인하기 위해, 여러분의 솔루션은 두 번 실행됩니다.
첫 번째 실행
첫 번째 실행 동안, 여러분의 프로그램은 입력으로 $n$개의 RBS를 받습니다. 각 RBS는 어떤 루트 트리의 코드 $s_i$입니다. 이에 응답하여, 여러분의 프로그램은 어떤 루트 트리 $w$를 인코딩하는 RBS를 출력해야 합니다. 서로 다른 서브태스크에서는 원래 트리들의 총 정점 수에 따라 트리 $w$의 정점 수에 서로 다른 제약이 적용됩니다.
두 번째 실행
두 번째 실행 동안, 여러분의 프로그램은 첫 번째 실행에서 출력한 트리 $w$를 인코딩하는 단일 RBS를 입력으로 받습니다. 첫 번째 실행에서 프로그램이 출력한 RBS가 아니라, 트리 $w$를 인코딩하는 임의의 유효한 RBS가 입력으로 제공될 수 있습니다.
이에 응답하여, 여러분의 프로그램은 첫 번째 실행에서 제공된 것과 동일한 트리들을 인코딩하는 RBS들을 같은 순서로 출력해야 합니다. 각 트리에 대해, 그 트리를 인코딩하는 임의의 RBS를 출력할 수 있지만, 트리 자체의 순서는 첫 번째 실행과 동일해야 합니다.
인터랙션
각 실행이 시작될 때, 프로그램은 실행 번호인 $t$ (1 또는 2)를 읽어야 합니다.
첫 번째 실행
첫 번째 실행 동안 여러분은 여러 개의 테스트 케이스를 처리해야 합니다. 각 테스트 케이스는 표준 입력에 인터랙티브하게 제공됩니다. 즉, 다음 테스트 케이스를 읽기 전에 프로그램은 이전 모든 테스트 케이스에 대한 답을 출력하고 표준 출력 버퍼를 플러시해야 합니다.
각 테스트 케이스의 첫 번째 줄에는 인코딩할 트리의 개수인 단일 정수 $n$이 포함됩니다. $n$이 $0$이면 모든 테스트 케이스가 처리되었으며 프로그램이 종료되어야 함을 의미합니다. 그렇지 않으면 다음 $n$개의 줄에 트리에 대한 설명이 포함됩니다.
각 트리는 문자 "("와 ")"로 구성된 단일 문자열 $s_i$로 지정됩니다. 이 $s_i$는 문제 설명에 설명된 방식으로 $i$번째 트리를 인코딩하는 RBS입니다. $s_i$는 유효한 트리를 지정함이 보장됩니다.
각 테스트 케이스에 대해 프로그램은 어떤 트리 $w$를 인코딩하는 RBS를 출력해야 합니다. 트리를 출력한 후에는 개행 문자를 출력하고 출력 버퍼를 플러시해야 합니다.
이 문제에서 첫 번째 실행 동안 채점 프로그램의 동작은 적응적(adaptive)입니다. 즉, 첫 번째 실행 동안 채점 프로그램은 현재 테스트의 이전 테스트 케이스에서 여러분이 출력한 트리 $w$를 사용하여 새로운 테스트 케이스를 생성할 수 있습니다.
두 번째 실행
두 번째 실행 동안 여러분은 여러 개의 테스트 케이스를 처리해야 합니다.
각 테스트 케이스는 문자열 $s$로 지정됩니다. 문자열 $s$가 "0"이면 모든 테스트 케이스를 처리했으며 프로그램이 종료되어야 합니다.
그렇지 않으면 $s$는 첫 번째 실행에서 프로그램이 구성한 어떤 트리 $w$를 인코딩하는 RBS입니다.
이러한 각 트리에 대해, 여러분은 별도의 줄에 단일 정수 $n$ — 디코딩된 트리의 개수를 출력해야 합니다.
다음 줄에는 첫 번째 실행에서 제공된 $s_1, \ldots, s_n$ 문자열로 인코딩된 것과 동일한 트리들을 인코딩하는 $n$개의 RBS를, 해당 순서대로, 단일 줄에 "+" 문자로 구분하여 출력해야 합니다. 예를 들어, RBS "(())"와 "(()())"를 그 순서대로 출력해야 한다면, 첫 번째 줄에는 "2", 두 번째 줄에는 "(()())+(()())"를 출력해야 합니다.
$n$을 출력하고 트리를 설명하는 문자열을 출력한 후에는 개행 문자를 출력하고 출력 버퍼를 플러시해야 합니다.
두 번째 실행의 각 테스트 케이스에서 여러분의 프로그램은 첫 번째 실행 중에 얻어진 트리 중 임의의 트리를 제공받을 수 있습니다.
참고
각 출력 후에 개행 문자를 출력하는 것을 잊지 마십시오. 인터랙티브 문제에서 출력 버퍼를 올바르게 플러시하는 방법은 참가자 가이드를 참조하십시오.
서브태스크
$s$를 단일 테스트 케이스에 있는 RBS의 총 길이, $m$을 이 테스트 케이스에 대한 첫 번째 실행에서 프로그램의 출력 크기라고 합시다. 각 서브태스크에 대해 함수 $f(x)$가 정의됩니다. 서브태스크는 각 테스트 케이스에 대해 $m \leq f(s)$가 성립하고 모든 트리가 올바르게 재구성된 경우 통과된 것으로 간주됩니다.
$t_i$를 $i$번째 트리의 정점 개수라고 합시다. 그러면 문자열 $s_i$의 길이는 $2t_i$입니다.
$S$를 하나의 테스트에 있는 모든 테스트 케이스의 $s$ 합계라고 합시다. 각 테스트에서 $S$가 $10^6$을 초과하지 않으며 테스트 케이스의 개수는 $100$을 초과하지 않음이 보장됩니다.
| 서브태스크 | 점수 | $f(x)$ | $S$ | 추가 조건 | 필요 서브태스크 |
|---|---|---|---|---|---|
| 1 | 13 | $f(x) = x + 2000$ | $S \le 200\,000$ | 두 번째 실행 동안 제공되는 RBS는 첫 번째 실행에서 여러분의 솔루션이 출력한 것과 정확히 동일합니다. | |
| 2 | 7 | $f(x) = x + 2000$ | $S \le 200\,000$ | $t_1 < t_2 < \ldots < t_n$ | |
| 3 | 6 | $f(x) = x + 2000$ | $S \le 200\,000$ | $n = 2$ | |
| 4 | 최대 34 | $f(x) = 4 \cdot x + 2000$ | $S \le 200\,000$ | ||
| 5 | 최대 11 | $f(x) = x + 2000$ | $t_1 = t_2 = \ldots = t_n > 1$ | ||
| 6 | 최대 9 | $f(x) = x + 2000$ | $t_i > 1$ | 5 | |
| 7 | 최대 20 | $f(x) = x + 2000$ | 1 -- 6 |
네 번째 서브태스크는 다음 공식에 따라 채점됩니다. 각 테스트 케이스에 대해 $k = \max\left(0, \dfrac{m - 2000}{s}\right)$라고 정의합니다. 함수 $\operatorname{score}(k)$는 다음과 같이 정의됩니다:
| $k$ | $\operatorname{score}(k)$ |
|---|---|
| $\leq 1{,}5$ | $34$ |
| $2$ | $20$ |
| $3$ | $10$ |
| $4$ | $5$ |
| $> 4$ | $0$ |
$k$의 중간 값에 대해서는 함수가 표의 인접한 행 사이에서 선형으로 계산되며 가장 가까운 정수로 반올림됩니다.
테스트에 대한 점수는 테스트의 모든 테스트 케이스 중 $\operatorname{score}(k)$의 최솟값과 같습니다. 서브태스크에 대한 점수는 이 서브태스크의 테스트 점수 중 최솟값과 같습니다.
서브태스크 5, 6, 7도 공식을 사용하여 채점됩니다. 각 테스트 케이스에 대해 $c = \max(0, m - s)$라고 정의합니다. 함수 $\operatorname{score}(c)$는 다음과 같이 정의됩니다:
| $c$ | $\operatorname{score}(c)$, 서브태스크 5 | $\operatorname{score}(c)$, 서브태스크 6 | $\operatorname{score}(c)$, 서브태스크 7 |
|---|---|---|---|
| $\leq 30$ | $11$ | $9$ | $20$ |
| $100$ | $7$ | $7$ | $14$ |
| $200$ | $4$ | $4$ | $8$ |
| $2000$ | $2$ | $2$ | $4$ |
| $> 2000$ | $0$ | $0$ | $0$ |
$c$의 중간 값에 대해서는 함수가 표의 인접한 행 사이에서 선형으로 계산되며 가장 가까운 정수로 반올림됩니다.
테스트에 대한 점수는 테스트의 모든 테스트 케이스 중 $\operatorname{score}(c)$의 최솟값과 같습니다. 서브태스크에 대한 점수는 이 서브태스크의 테스트 점수 중 최솟값과 같습니다.
예제
입력 1
1 3 () (()) (()()) 1 ((())()) 0
출력 1
((()(()()))) ((((((((()))))))))
입력 2
2 ((((((((())))))))) (((()())())) 0
출력 2
1 (()(())) 3 ()+(())+(()())