Jest to problem interakcyjny z dwukrotnym uruchomieniem (podwójne wykonanie).
W tym zadaniu rozważamy nieuporządkowane drzewa ukorzenione. Nieuporządkowane drzewo ukorzenione składa się z korzenia, który może mieć zero lub więcej dzieci. Każde dziecko z kolei jest nieuporządkowanym drzewem ukorzenionym. Jak sugeruje nazwa, kolejność wypisywania dzieci nie ma znaczenia. Oznacza to, że drzewa pokazane na poniższym rysunku są tym samym nieuporządkowanym drzewem ukorzenionym. W dalszej części będziemy nazywać nieuporządkowane drzewa ukorzenione po prostu drzewami.
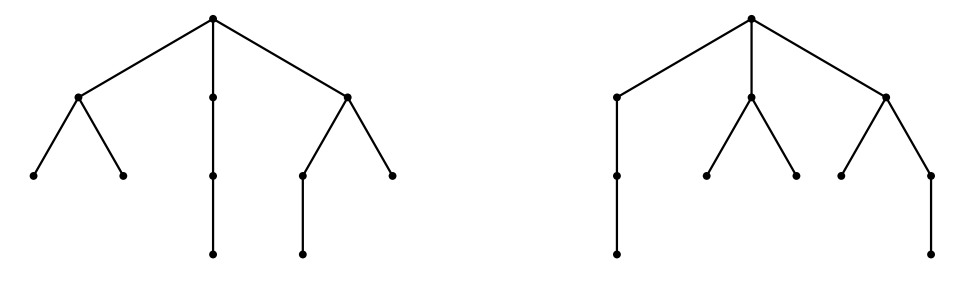
Każde drzewo można zakodować jako regularny ciąg nawiasów (dalej RBS) w następujący sposób:
- Drzewo składające się z pojedynczego wierzchołka jest kodowane jako "
()". - Załóżmy, że po usunięciu korzenia drzewo dzieli się na poddrzewa $t_1, t_2, \ldots, t_k$, gdzie $k$ to liczba dzieci korzenia oryginalnego drzewa. Niech $s_1, \ldots, s_k$ będą ciągami kodującymi drzewa $t_1, \ldots, t_k$. Wtedy dla dowolnej permutacji $a=[a_1, a_2, ..., a_k]$ liczb od $1$ do $k$, oryginalne drzewo może być zakodowane przez RBS "
($s_{a_1}s_{a_2}\ldots s_{a_k}$)".
Zauważ, że to samo drzewo może być zakodowane przez różne RBS-y. Na przykład drzewo pokazane na poniższym rysunku może być zakodowane przy użyciu RBS "(()(()))" lub "((())())".
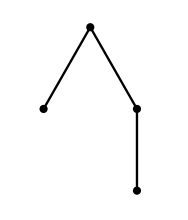
Musisz nauczyć się kodować dowolny ciąg drzew $u_1, \ldots, u_n$ jako pojedyncze ukorzenione drzewo $w$. Aby zweryfikować poprawność twojej metody kodowania, twoje rozwiązanie zostanie uruchomione dwukrotnie.
Pierwsze uruchomienie
Podczas pierwszego uruchomienia twój program otrzymuje na wejściu $n$ RBS-ów, każdy reprezentujący kod $s_i$ pewnego ukorzenionego drzewa. W odpowiedzi twój program musi wypisać RBS kodujący jakieś ukorzenione drzewo $w$. W różnych podzadaniach nakładane są różne ograniczenia na liczbę wierzchołków w drzewie $w$ w zależności od całkowitej liczby wierzchołków w oryginalnych drzewach.
Drugie uruchomienie
Podczas drugiego uruchomienia twój program otrzymuje pojedynczy RBS kodujący drzewo $w$, które twój program wypisał podczas pierwszego uruchomienia. Zauważ, że dowolny poprawny RBS kodujący drzewo $w$ może zostać podany na wejściu, niekoniecznie ten, który został wypisany przez twój program podczas pierwszego uruchomienia.
W odpowiedzi twój program musi wypisać RBS-y kodujące te same drzewa, które zostały podane podczas pierwszego uruchomienia, w tej samej kolejności. Dla każdego drzewa możesz wypisać dowolny kodujący je RBS, ale kolejność drzew w ciągu musi być taka sama jak w pierwszym uruchomieniu programu.
Interakcja
Na początku każdego uruchomienia twój program musi wczytać pojedynczą liczbę całkowitą $t$, równą 1 lub 2 – numer uruchomienia.
Pierwsze uruchomienie
Podczas pierwszego uruchomienia musisz przetworzyć wiele zestawów danych. Każdy zestaw danych jest podawany na standardowe wejście interakcyjnie, co oznacza, że przed wczytaniem następnego zestawu twój program musi wypisać odpowiedź dla wszystkich poprzednich zestawów i opróżnić bufor standardowego wyjścia.
Pierwszy wiersz każdego zestawu danych zawiera pojedynczą liczbę całkowitą $n$ – liczbę drzew do zakodowania. Jeśli $n$ jest równe $0$, oznacza to, że wszystkie zestawy danych zostały przetworzone i program powinien się zakończyć. W przeciwnym razie kolejne $n$ wierszy zawiera opisy drzew.
Każde drzewo jest określone przez pojedynczy ciąg $s_i$ składający się ze znaków "(" i ")" – RBS kodujący $i$-te drzewo w sposób opisany w treści zadania. Gwarantowane jest, że $s_i$ określa poprawne drzewo.
Dla każdego zestawu danych program musi wypisać RBS kodujący jakieś drzewo $w$. Po wypisaniu drzewa należy wypisać znak nowej linii i opróżnić bufor wyjścia.
W tym zadaniu zachowanie programu jury podczas pierwszego uruchomienia jest adaptacyjne. Oznacza to, że program jury podczas pierwszego uruchomienia może wykorzystywać drzewa $w$ wypisane przez ciebie w poprzednich zestawach danych bieżącego testu przy generowaniu nowego zestawu danych.
Drugie uruchomienie
Podczas drugiego uruchomienia musisz przetworzyć wiele zestawów danych. Każdy zestaw danych jest określony przez ciąg $s$. Jeśli ciąg $s$ jest równy "0", oznacza to, że przetworzyłeś wszystkie zestawy danych i program powinien się zakończyć. W przeciwnym razie $s$ zawiera pewien RBS kodujący jakieś drzewo $w$, które program skonstruował podczas pierwszego uruchomienia.
Dla każdego takiego drzewa musisz wypisać w osobnym wierszu pojedynczą liczbę całkowitą $n$ – liczbę odkodowanych drzew.
W następnym wierszu musisz wypisać $n$ RBS-ów kodujących, w odpowiedniej kolejności, te same drzewa, które były zakodowane przez ciągi $s_1, \ldots, s_n$ podane podczas pierwszego uruchomienia, w jednym wierszu, oddzielając je znakiem "+". Na przykład, jeśli musisz wypisać RBS-y "(())" i "(()())" w tej kolejności, wyjście powinno wyglądać następująco: w pierwszym wierszu "2", a w drugim "(()())+(()())".
Po wypisaniu liczby $n$ i wypisaniu ciągu opisującego drzewa należy wypisać znak nowej linii i opróżnić bufor wyjścia.
W każdym z zestawów danych w drugim uruchomieniu twój program może otrzymać dowolne z drzew uzyskanych podczas pierwszego uruchomienia.
Uwagi
Nie zapomnij wypisać znaku nowej linii po każdym wyjściu. Zapoznaj się z poradnikiem dla uczestnika, aby dowiedzieć się, jak prawidłowo opróżniać bufor wyjścia w problemach interakcyjnych.
Podzadania
Niech $s$ będzie całkowitą długością RBS-ów w pojedynczym zestawie danych, a $m$ rozmiarem wyjścia twojego programu podczas pierwszego uruchomienia dla tego zestawu danych. Dla każdego podzadania zdefiniowana jest funkcja $f(x)$. Podzadanie uważa się za zaliczone, jeśli dla każdego zestawu danych zachodzi $m \leq f(s)$, a także jeśli wszystkie drzewa zostały poprawnie zrekonstruowane.
Niech $t_i$ będzie liczbą wierzchołków w $i$-tym drzewie. Wtedy długość ciągu $s_i$ wynosi $2t_i$.
Niech $S$ będzie sumą $s$ po wszystkich zestawach danych pojedynczego testu. Gwarantowane jest, że w każdym teście $S$ nie przekracza $10^6$, a liczba zestawów danych nie przekracza $100$.
| Podzadanie | Punkty | $f(x)$ | $S$ | Dodatkowe | Wymagane podzadania |
|---|---|---|---|---|---|
| 1 | 13 | $f(x) = x + 2000$ | $S \le 200\,000$ | Podczas drugiego uruchomienia podane RBS-y są identyczne z tymi, które zostały wypisane przez twoje rozwiązanie podczas pierwszego uruchomienia. | |
| 2 | 7 | $f(x) = x + 2000$ | $S \le 200\,000$ | $t_1 < t_2 < \ldots < t_n$ | |
| 3 | 6 | $f(x) = x + 2000$ | $S \le 200\,000$ | $n = 2$ | |
| 4 | do 34 | $f(x) = 4 \cdot x + 2000$ | $S \le 200\,000$ | ||
| 5 | do 11 | $f(x) = x + 2000$ | $t_1 = t_2 = \ldots = t_n > 1$ | ||
| 6 | do 9 | $f(x) = x + 2000$ | $t_i > 1$ | 5 | |
| 7 | do 20 | $f(x) = x + 2000$ | 1 -- 6 |
Czwarte podzadanie oceniane jest według następującego wzoru. Niech $k = \max\left(0, \dfrac{m - 2000}{s}\right)$ dla każdego zestawu danych. Definiujemy funkcję $\operatorname{score}(k)$ następująco:
| $k$ | $\operatorname{score}(k)$ |
|---|---|
| $\leq 1{,}5$ | $34$ |
| $2$ | $20$ |
| $3$ | $10$ |
| $4$ | $5$ |
| $> 4$ | $0$ |
Dla pośrednich wartości $k$ funkcja jest obliczana liniowo między sąsiednimi wierszami tabeli i zaokrąglana do najbliższej liczby całkowitej.
Wynik za test jest równy minimum $\operatorname{score}(k)$ po wszystkich zestawach danych w teście. Wynik za podzadanie jest równy minimum wyników testów w tym podzadaniu.
Podzadania 5, 6 i 7 również oceniane są według wzoru. Niech $c = \max(0, m - s)$ dla każdego zestawu danych. Definiujemy funkcję $\operatorname{score}(c)$ następująco:
| $c$ | $\operatorname{score}(c)$, podzadanie 5 | $\operatorname{score}(c)$, podzadanie 6 | $\operatorname{score}(c)$, podzadanie 7 |
|---|---|---|---|
| $\leq 30$ | $11$ | $9$ | $20$ |
| $100$ | $7$ | $7$ | $14$ |
| $200$ | $4$ | $4$ | $8$ |
| $2000$ | $2$ | $2$ | $4$ |
| $> 2000$ | $0$ | $0$ | $0$ |
Dla pośrednich wartości $c$ funkcja jest obliczana liniowo między sąsiednimi wierszami tabeli i zaokrąglana do najbliższej liczby całkowitej.
Wynik za test jest równy minimum $\operatorname{score}(c)$ po wszystkich zestawach danych w teście. Wynik za podzadanie jest równy minimum wyników testów w tym podzadaniu.
Przykład
Wejście 1
1 3 () (()) (()()) 1 ((())()) 0
Wyjście 1
((()(()()))) ((((((((()))))))))
Wejście 2
2 ((((((((())))))))) (((()())())) 0
Wyjście 2
1 (()(())) 3 ()+(())+(()())